
This is written in collaboration with the team at Ingonyama. Special thanks to @jeremyfelder for making this happen.
ZKML with Acceleration
We’ve recently integrated the open-source Icicle GPU acceleration library built by the Ingonyama team. This enables developers to leverage hardware acceleration with a simple environment configuration.
The integration is a strategic enhancement to the EZKL engine, addressing the computational bottlenecks inherent in current ZK proof systems. It is especially relevant for large circuits, like those generated for machine learning models.
We observe a ~98% reduction in MSM times against baseline CPU runs for aggregate circuits, and a ~35% reduction in total aggregate proof time against baseline CPU prover times.
This is the first step in a comprehensive hardware integration. With the Ingonyama team, we’re continuing to work towards full range support for GPU operations. And further, we’re working towards integration with alternative hardware providers — ideally demonstrating tangible benchmarks for the broader domain.
We provide context and technical specification below. Or feel free to jump right into the libraries here.
Zero Knowledge Bottlenecks
Citing Hardware Review: GPUs, FPGAs, and Zero Knowledge Proofs, there are two components to zero knowledge applications:
- DSLs and Low-Level Libraries: These are essential for expressing computations in a ZK-friendly manner. Examples include Circom, Halo2, Noir, and low-level libraries like Arkworks. These tools convert programs into constraint systems (or read more here), where operations like addition and multiplication are represented as single constraints. Bit manipulation is trickier, requiring many more constraints.
- Proving Systems: They play a crucial role in generating and verifying proofs. Proving systems process inputs like Circuit, witness, and parameters. Generalized systems include Groth16 and PLONK, while specialized systems like EZKL cater to specific inputs like machine learning models.
The major bottlenecks in in the most widely deployed ZK systems are:
- Multi-scalar Multiplications (MSMs): Large-scale multiplications over vectors, consuming significant time and memory, even when parallelized.
- Fast Fourier Transforms (FFTs): Algorithms that require frequent data shuffling, making them challenging to accelerate, especially on distributed infrastructure.
The Role of Hardware
Hardware accelerations, such as GPUs and FPGAs, offer significant advantages over software optimizations by enhancing parallelism and optimizing memory access:
- GPUs: Provide rapid development and massive parallelism, but are power-intensive.
- FPGAs: Offer lower latency, especially for large data streams, and are more energy-efficient but have a complex development cycle.
For more extensive discussion around optimal hardware design and performance, see here. The domain is evolving rapidly and many approaches remain competitive.
GPU-Acceleration for Halo2
In the Halo2 proof system, bottlenecks can vary depending on the specific circuit being proven. These bottlenecks fall into two main categories:
- Commitment Bottlenecks (MSM): These are primarily computational bottlenecks and are often parallelizable. In circuits where MSM is the bottleneck, we observe a level of universality. This means that applying a GPU-accelerated solution can efficiently resolve these bottlenecks with minimal modifications to the existing codebase.
- Constraint Evaluation Bottlenecks (especially in h poly): These bottlenecks are more complex as they can be either computational or memory-intensive. They heavily depend on the specifics of the circuit. Addressing these requires a tailored redesign of the evaluation algorithm. The focus here is on optimizing the trade-off between memory usage and computation, and deciding whether to store intermediate results or recompute them.

A prime example is the KZG aggregation circuit. In such circuits, the primary challenge lies in the accumulation of elliptic curve group elements. The constraints in these cases are relatively uniform and of low degree (e.g., incomplete addition formulae with degree 4 constraints as per Halo2 documentation).
Thus, the bulk of the complexity arises from commitments (MSM), a computational problem effectively solvable with GPU acceleration.
For the scope of this integration, we’ve chosen to focus on commitment bottlenecks. It’s low hanging fruit, but also an optimization for a core component of the engine (KZG aggregation). This is only one step — there remains a lot of work to be done.
Icicle: CUDA-Enabled GPUs
The team at Ingonyama has developed Icicle as an open-source library designed for ZK acceleration using CUDA-enabled GPUs. CUDA, or Compute Unified Device Architecture, is a parallel computing platform and API model created by Nvidia. It allows software to utilize Nvidia GPUs for general-purpose processing. The primary objective of Icicle is to offload a significant portion of the prover code to the GPU and harnesses parallel processing power.
Icicle hosts APIs in Rust and Golang, which simplifies integration. The design is also customizable, featuring:
- High-Level API: For common tasks like committing, evaluating, and interpolating polynomials.
- Low-Level API: Targeted at specific operations like Multi-Scalar Multiplications (MSM), Number Theoretic Transforms (NTT), and Inverse NTTs (INTT).
- GPU Kernels: For optimized execution of specific tasks on the GPU.
Notably, Icicle supports essential functionalities like:
- Vectorized Field/Group Arithmetic: Efficient handling of mathematical operations over fields and groups.
- Polynomial Arithmetic: Critical for many ZK algorithms.
- Hash Functions: Essential for cryptographic applications.
- Complex Structures: Like Inverse Elliptic Curve Number Theoretic Transforms (I/ECNTT), Batched MSM, and Merkle trees.
Integration with EZKL
The Icicle library has been seamlessly integrated with the EZKL engine, offering GPU acceleration for users with direct access to NVIDIA GPUs or simply with access to Colab. This integration enhances the performance of the EZKL engine by leveraging the parallel processing capabilities of GPUs. Here’s how to enable and manage this feature:
- Enabling GPU Acceleration: To activate GPU acceleration, build the system with the
iciclefeature and set the environment variable as follows:
export ENABLE_ICICLE_GPU=true
- Reverting to CPU: To switch back to CPU processing, simply unset the
ENABLE_ICICLE_GPUenvironment variable rather than setting it to false:
unset ENABLE_ICICLE_GPU
- Customizing Threshold for Small Circuits: If you wish to modify the threshold for what constitutes a small circuit, you can set the
ICICLE_SMALL_Kenvironment variable to a desired value. This allows for greater control over when GPU acceleration is employed.
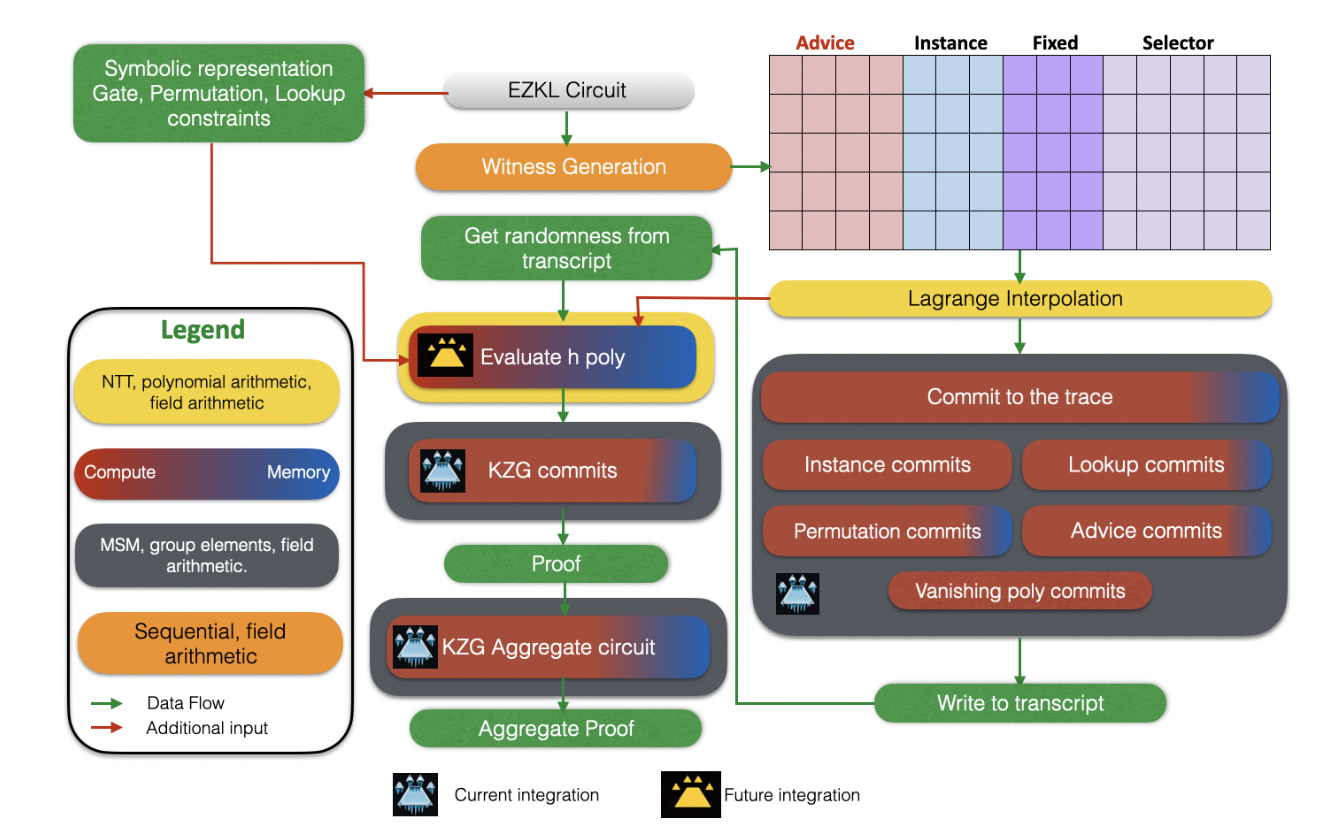
Current ICICLE integration overview. This integration targets compute bottlenecks due to MSM, with significant effects visible in the KZG aggregate circuit.
Key Affordances
This integration provides several technical affordances.
Most importantly, the integration supports plug and play MSM operations in the GPU using the Icicle library. As a target and testing environment, we focused on replacing CPU-based KZG commitments in the EZKL’s aggregation command. This is where multiple proofs are consolidated into a single proof. More specifically, commit and commit_lagrange for KZG commitments (done on the CPU) with MSM operations (on the GPU) for the BN254 elliptic curve.
We have also enabled environment variables and crate features, allowing developers to toggle between CPU and GPU for different circuits on the same binary/build of EZKL. In order to optimize GPU toggling, GPU acceleration is only enabled by default for large k circuits (k > 8).
Benchmarking Results
Our benchmarking results demonstrate a substantial improvement in performance with the integration of the Icicle library into the EZKL engine:
- Significant Reduction in MSM Times: We observed approximately a 98% reduction in Multi-Scalar Multiplication (MSM) times when compared to the baseline CPU run for the aggregate circuit. This indicates a highly efficient offloading of computational tasks to the GPU.
- Dramatic Speed Increase in MSM Operations: The MSM operations performed by ICICLE are, on average, 50 times faster compared to those in the baseline CPU configuration. This speedup was consistent across most MSMs in the aggregate command.
- Overall Reduction in Proof Times: The total time required to generate aggregate proofs saw a reduction of about 35% when compared to the baseline CPU prover times. This reflects a significant overall performance enhancement in the proof generation process.
These results highlight the effectiveness of GPU acceleration in optimizing ZK proof systems, particularly in computational aspects like MSM operations. For verification, you can view our continuous integration tests here.
Future Directions
Looking ahead, we plan to further optimize and expand the capabilities of EZKL and Icicle integration:
- Expanding GPU Operations: One key area of focus will be replacing more CPU operations with GPU counterparts. This includes operations involving Number Theoretic Transforms (NTTs), which are currently CPU-based. By offloading these operations to the GPU, we expect to achieve even greater efficiency and speed.
- Introducing Batched Operations: Another crucial development will be the addition of batched operations. This enhancement is particularly aimed at enabling efficient GPU usage even in smaller and wider circuits. By doing so, we aim to extend the benefits of GPU acceleration to a broader range of circuit types and sizes, ensuring optimal performance across all scenarios.
More broadly, we seek to see integration with alternative hardware systems. This will enable functional benchmarking and developer flexibility for the broader domain.
Through these future developments, we aim to continue pushing the boundaries of performance in ZK proof systems, making them more efficient and accessible for a wider range of applications.
Appendix
Notes for Future Integrations
For contributors and developers, we tested this integration with the aggregate command tutorial on a custom instance with four proofs. A few notes for future integrations
- Benchmarking Environment: Tests were conducted using AWS c6a.8xlarge instances with AMD Epyc 7R13 for baseline CPU runs.
- Aggregation Command Tutorial: The integration’s performance was validated using the aggregation command tutorial, including a test instance with 4 proofs for baseline comparison.
- Initial Testing on Single MSM Instances: Initially, testing focused on single instances of MSM from the EZKL/halo2 crates to verify functionality.
- Issue with GPU Context in Full Proofs: Upon extending to full proofs, it was discovered that the GPU context was lost after a single operation. A solution was implemented by creating a static reference to maintain the GPU context throughout an entire proof command.
- Focus on Aggregation Circuit/Command: The integration primarily targeted the aggregation circuit/command, characterized by a large K (number of constraints) and a small number of advice columns.
- Impact on Proof Command: Modifications in the code affected the proof command as well. It became necessary to ensure that the performance of single proofs was either maintained or improved with these changes.
- Performance Variations Based on Circuit Size and Width: For large and narrow circuits, the GPU enhancements yielded positive results. However, for smaller (K ≤ 8) and wider circuits, the GPU enhancements led to slower performance.
- Future Improvements for Universal Optimization: Plans are in place to enhance GPU integration for all circuit types, particularly focusing on batching operations for optimal performance across various circuit dimensions.