
Disclaimer: In the interest of transparency and rigor, please note that this benchmarking was conducted by the team at EZKL and includes the EZKL framework.
We have documented all procedures and results in this analysis to facilitate replicability. The frameworks included are publicly available, and we encourage independent or third-party replication of this experiment.
Introduction
Zero knowledge machine learning (ZKML) is an application of zero knowledge proofs (ZKPs) to verify computations produced by machine learning models. Zero knowledge proofs are a cryptographic mechanism for proving the truth of statements without conveying information beyond the statement’s truth to a verifier. With regards to machine learning, ZKPs enable proof that an output was generated by a specific model. This becomes applicable as ML models proliferate and their outputs drive critical decisions.
While ZKML has experienced significant attention in the past year, it remains an early-stage technology in research & development. There are currently several open and closed-source frameworks for ZKML, differing primarily on their choice of proving system. Implementation itself is also relevant, as certain optimizations around model ingestion, pruning, hashing, amongst others, have amplified impact on memory usage and proving time at scale.
Given a smaller subset of frameworks for ZKML relative to the broader ZKP landscape, we receive frequent inquiries on the comparative performance of different ZKML frameworks. Our objective is to address this gap benchmarking and comparative analysis by comparing EZKL to two other popular ZKML solutions with relatively broad support for different ML model classes: Orion and RISC Zero.
The main findings of this benchmark are as follows:
- Setup: The setup complexity varied across frameworks. EZKL demonstrated a more user-friendly setup process, while RISC Zero and Orion presented more involved setups.
- Proving time: Across different models, proving times varied, with EZKL demonstrating an average speed 65.88x faster than RISC Zero and 2.92x faster than Orion.
- Memory usage: Memory efficiency also varied across frameworks. On average, EZKL used 63.95% less memory than Orion and 98.13% less than RISC Zero.
- Model accuracy: The frameworks demonstrated different capabilities in balancing accuracy with ZKML constraints. A key consideration is allowance for adjustable precision in quantization, which impacts the trade-off between accuracy and proving efficiency.
Methodology
There are a number of existing repositories focused on ZKP system benchmarking, including those published or proposed by teams at Delendum, Polybase Labs, and Ingonyama. These are primarily concerned with benchmarking via elliptic curve operations, circuit types, hashing schemes, and other test vectors. We do not evaluate these benchmarks here, and an extended discussion of the mechanics around underlying ZKP systems is beyond the scope of this study. Instead, we focus on comparing a specific type of ZKP application, ZKML.
Metrics: For benchmarking the setup experience, we present our observations. We invite replicating developers or researchers to form their own opinions on the respective processes.
For benchmarking the proving process, we focus on the following key metrics:
- Proving Time: The duration required to generate a proof for a given model.
- Memory Usage: The amount of memory consumed during the proof generation process.
These metrics seek to evaluate the practical applicability and efficiency of ZKML frameworks in real-world scenarios. Note that for this study, we omit verification time as a metric. It would merit a discussion around both on and off-chain verification methods, which is also beyond the scope.
Frameworks: The primary frameworks included in this study are:
- EZKL Engine: Since EZKL is the framework we are most familar with, and given it’s public development history, we have used it as a baseline for our benchmarking. EZKL converts ONNX files into zkSNARK circuits via Halo2 for inference.
The Open Neural Network Exchange (ONNX) is an open-source format where models are represented as computational graphs. This simplifies conversion into circuits. More extensive discussion around ONNX for ZK purposes is here.
- RISC0’s SmartCore ML: This framework ingests models created via the SmartCore machine learning Rust crate and performs inference via the RISC Zero ZKVM.
- Giza’s Orion: This framework also converts ONNX files, but leverages zkSTARKs instead via Cairo for inference.
The frameworks excluded from the study are:
- Modulus Lab’s Remainder Prover: This framework is closed-source at the time of writing, and therefore unavailable for public benchmarking.
- Aleo’s Transpiler: This framework has limited model architecture coverage, with support only for decision tree classifiers and small MLP neural networks. It is excluded in order to accomodate the four models detailed below.
- Additional frameworks include Ritual, Inference Labs, Spectral, Vanna Labs. These frameworks all leverage the EZKL engine for inference, and therefore present redundant benchmarking.
Models: For each framework, the benchmarking utilizes four model types to test proving time and memory usage: Linear Regression, Random Forest Classification, Support Vector Machine (SVM) Classification, and Tree Ensemble Regression. We limit the benchmarking to these four models, as these are the only models compatible with all tested frameworks.
Selecting these four models required finding models supported under the SmartCore used by RISC Zero and exportable to the ONNX format used by EZKL and Orion.
One constraint is around the robustness of the SmartCore library. There are a limited amount of supported models, as they must be explicitly defined in Rust with specifications on parameters and data types. The Python / Javascript library ecosystems are more extensive, given that abstraction enables smoother developer experience.
Another constraint is around the ONNX operations supported by EZKL and Orion. Orion does not currently support the Conv operation, which is necessary for convolution models.
As a consequence, more complex models like neural networks are currently beyond benchmarking scope. For a comprehensive list of models we considered, reference our discussions on transformer-based and tree-based models.
Replicability: We provide a few mechanisms to reproducing these benchmarking results on your local machine:
- Clone the benchmarking repository or open the benchmarking Jupyter notebook.
- Ensure your machine has at least 16 GB of RAM, or access through Google Colab.
- Allocate a few hours for the completion of the entire benchmarking process.
Results
We tested four model types across three frameworks. Note that for Random Forest Model, we cannot produce results for the Orion framework due to out-of-memory errors. A longer discussion is presented in the analysis. The results are as follows:
Linear Regression
| Framework | Memory Usage (avg) | Memory Usage (std) | Proving Time (avg) | Proving Time (std) |
|---|---|---|---|---|
| ezkl | 19.375mb | 0.102mb | 0.118s | 0.009s |
| orion | 58.778mb | 0.098mb | 0.548s | 0.010s |
| riscZero | 1320.916mb | 0.696mb | 10.028s | 0.093s |
For linear regression, EZKL proving time is approximately 4.65x faster than Orion and 85.13x faster than RISC Zero. EZKL utilizes approximately 67.04% less memory than Orion and 98.53% less than RISC Zero.
Random Forest Classification
| Framework | Memory Usage (avg) | Memory Usage (std) | Proving Time (avg) | Proving Time (std) |
|---|---|---|---|---|
| ezkl | 382.782mb | 1.358mb | 6.161s | 0.262s |
| riscZero | 10189.338mb | 0.209mb | 173.398s | 1.639s |
For random forest classification, EZKL proving time is approximately 28.14x faster than RISC Zero. EZKL utilizes approximately 96.24% less memory than RISC Zero. Orion results are excluded here, for reasons explained in the analysis.
SVM classifications
| Framework | Memory Usage (avg) | Memory Usage (std) | Proving Time (avg) | Proving Time (std) |
|---|---|---|---|---|
| ezkl | 23.689mb | 0.118mb | 0.318s | 0.027s |
| orion | 58.815mb | 0.084mb | 0.667s | 0.011s |
| riscZero | 5107.030mb | 0.830mb | 37.453s | 0.332s |
For SVM classification, EZKL proving time is approximately 2.09x faster than Orion and 117.59x faster than RISC Zero. EZKL utilizes approximately 59.72% less memory than Orion and 99.54% less than RISC Zero.
Tree Ensemble Regression
| Framework | Memory Usage (avg) | Memory Usage (std) | Proving Time (avg) | Proving Time (std) |
|---|---|---|---|---|
| ezkl | 23.694mb | 0.089mb | 0.308s | 0.015s |
| orion | 67.595mb | 0.054mb | 0.961s | 0.056s |
| riscZero | 1320.766mb | 0.691mb | 10.062s | 0.062s |
For tree ensemble regression, EZKL proving time is approximately 2.92x faster than Orion and 65.88x faster than RISC Zero. EZKL utilizes approximately 63.95% less memory than Orion and 98.13% less than RISC Zero.
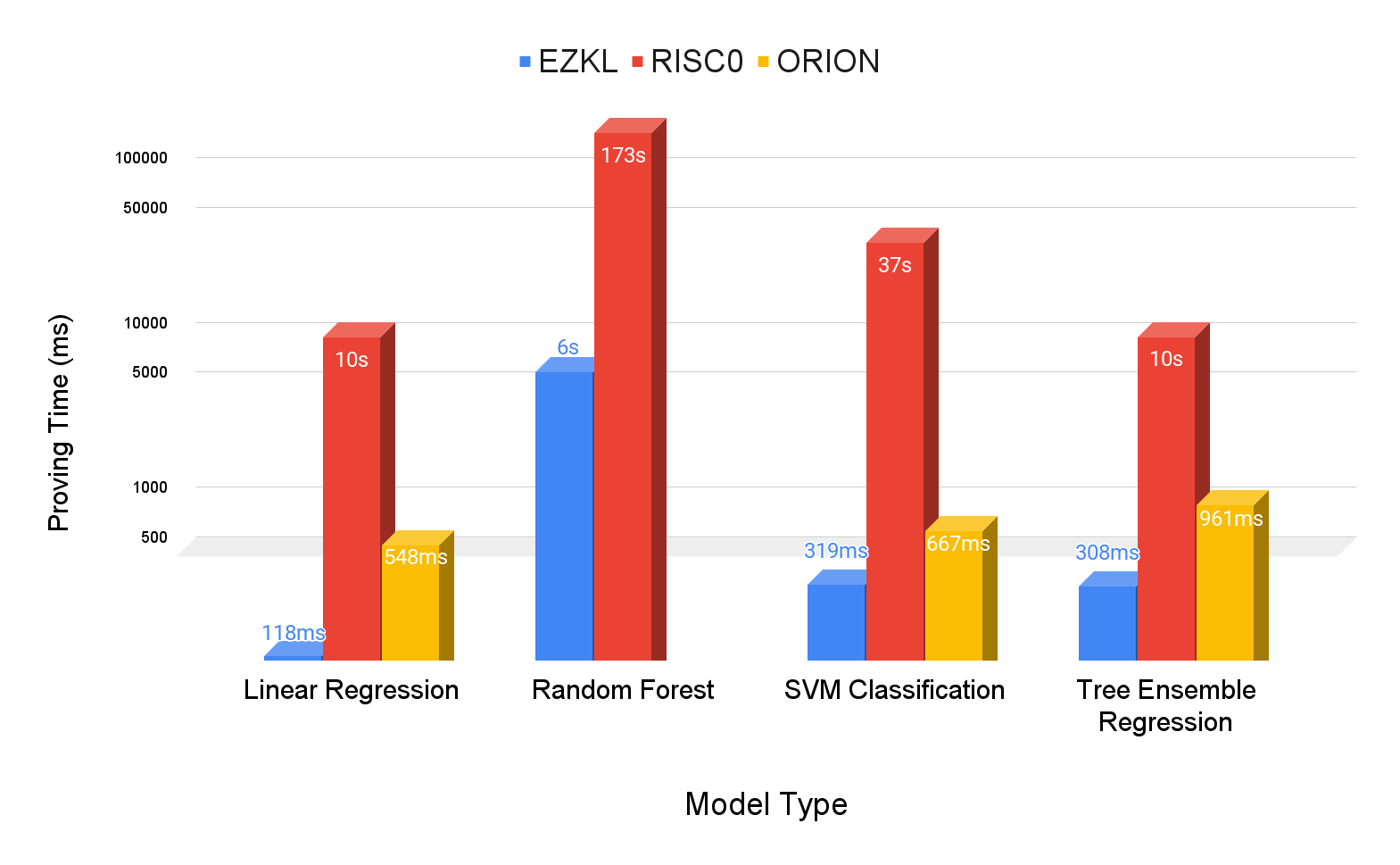
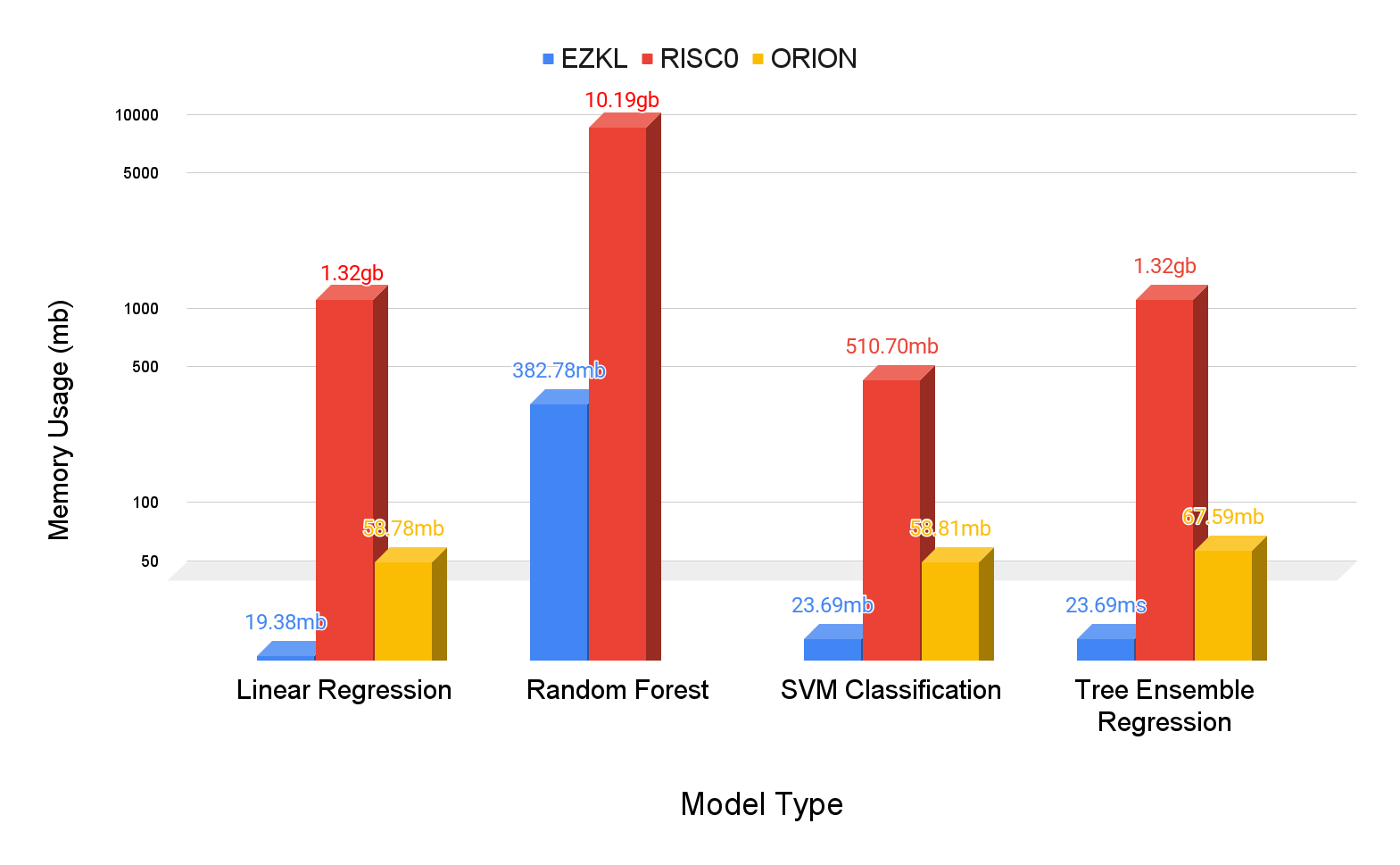
On average across models, EZKL is approximately 2.92x faster than Orion and about 65.88x faster than RISC Zero. EZKL consistently uses less memory, averaging 63.95% less than Orion and about 98.13% less than RISC Zero.
Analysis
Setup
We briefly compare the setup experience for using the frameworks and tooling provided open-source. As an common practice for AI/ML development, and also as exemplified across all the frameworks’ documentations, we predominantly use a Jupyter notebook environment. We’ve also combined these setups into one notebook for straightforward replicability and benchmarking.
EZKL
The setup process for EZKL may be entirely contained in a Jupyter notebook, which can be executed locally or via Google Colab. There are a number of example notebooks to fork. The setup procedure is guided, with users progressing through predefined notebook cells, executing code as instructed. The final step in the setup process involves running a ‘proving cell’, which generates zero-knowledge (zk) proofs based on the models and inputs provided in the notebook. In the benchmarking notebook, we simply forked an existing example notebook and adjusted the inputs to match the corresponding example SmartCore notebooks used by RISC Zero.
RISC Zero
The setup process for RISC Zero requires the user to establish a new RISCO zkVM (Zero Knowledge Virtual Machine) project. This setup is more complex than EZKL, as it necessitates the creation of a dedicated Rust-based Jupyter notebook server on the user’s computer, which is not supported by Google Colab.
In the Risc Zero environment, the user must define both a host and guest program for the ZKVM. The host program acts as an untrusted agent responsible for setting up the environment and managing inputs/outputs. The guest program contains the computations to be proven in the ZKVM. For benchmarking, users must first use the Jupyter notebook to prepare the model and input data, after which the host program can be run to execute the computations and generate proofs.
Orion
The setup process for Orion involves an initial installation of scarb, a development toolchain for Cairo and Starknet. This setup starts in a Python environment within a Jupyter notebook, similar to EZKL. Users set up their model and data in the notebook, then transfer this data into a Cairo file as a ‘Tensor’ using the Orion library. The next phase involves converting the model, initially created with numpy, into the Cairo language with Orion’s assistance. A cairo.inference file is then created for running the model in the Cairo environment, which is essential for timing the model’s execution and thereby determining the proving time.
Note: In the case of the Random Forest Classification benchmarks, it was not possible to obtain results for the Orion framework. Despite utilizing a testing environment with substantial resources, including 1000GB of RAM and a 64-core CPU, challenges were encountered when following the Orion framework’s recommended procedures. The process, as outlined in Orion’s documentation and demonstrated in this notebook, involves translating parameters from an ONNX TreeEnsembleClassifier model into Cairo code. During this process, repeated out-of-memory errors occurred, even when working with relatively small random forest models. This consistent issue points to a potential concern with memory management in the transpiler-generated Cairo program. A more thorough investigation is required to definitively determine the cause and possible solutions for this limitation.
Model Proving
To explain the significant difference in proving time and storage requirements, we briefly examine the underlying proof systems.
- RISC Zero: zkSTARK proof system using the FRI protocol, DEEP-ALI, and an HMAC-SHA-256 based PRF.
- Orion: zkSTARK proof system using Cairo.
- EZKL: zkSNARK proof system using Halo2, but swaps the default Halo2 lookup for the logUp lookup argument.
The performance efficiency observed in EZKL compared to RISC Zero and Orion can be partly attributed to specific technical implementations in EZKL’s design. One such feature is the utilization of lookup table arguments and efficient einsum operations within its Halo2 framework. EZKL employs lookup tables to represent non-linearities within circuits, which helps in reducing the proving costs. These tables provide pre-computed input-output pairs for non-linear operations, thereby simplifying complex computations during proof generation and potentially leading to quicker proving times.
Another aspect contributing to EZKL’s performance is its architectural difference from virtual machine (VM)-based systems like Cairo and RISC Zero. In VM-based frameworks, each computational step is executed individually, which can add to the overall proving overhead. For instance, processing 1000 nonlinear operations sequentially in a zkVM typically requires 1000 separate computations. In contrast, EZKL’s design bypasses this by employing a high-level approach that optimizes the handling of models and proofs, potentially allowing for circuit compilation with efficiencies akin to manual coding.
Model Accuracy
Another key consideration of benchmarking ZKML frameworks is maintaining consistent model accuracy when converting a model into an equivalent ZK-circuit.
In the case of RISC Zero, model inputs are processed as raw f64 values, with RISC Zero handling the quantization internally. The framework then sets the outputs as either u32 or i32, depending on the model. This process of quantization can affect the precision of computations, thereby influencing the final accuracy of the model.
EZKL, alternatively, allows users to adjust the fixed-point scaling factor, which converts floating-point values into fixed-point values for quantization. This feature enables users to find a balance between accuracy and proving efficiency, a crucial factor in applications where precision is as vital as computational efficiency.
Orion presents a different approach. It allows users to choose the fixed-point tensor type for inputting data into their models. In the benchmarks conducted for this study, a 2^4 (or 16 times) fixed-point scaling factor was used for Orion’s tensor library. To maintain comparability, the input scale parameter for EZKL was also set to 4, corresponding to 2^4. This calibration is essential to ensure that the model accuracy across different frameworks is on a comparable level and that the benchmarks are reflective of real-world usage scenarios.
Note: A limitation was noted with Orion: an issue in cairo-run’s handling of complex data prevented accurate output visualization in the Cairo benchmarks. This issue has been acknowledged by the Giza team, who are working towards a resolution.
Conclusion
The benchmark results indicate that EZKL exhibits notable performance efficiencies over RISC0 and Orion in terms of proving times for various models. Key factors contributing to this efficiency include the implementation of efficient logUP and einsum arguments and its non-virtual machine (non-VM) approach. These technical aspects suggest that EZKL may be well-suited for applications where rapid proof generation is a priority, and it also appears to support a broader range of models.
In terms of workflow, EZKL facilitates the execution of the entire data science and zero-knowledge pipeline within a single Jupyter notebook environment. In comparison, frameworks like RISC Zero and Orion typically require a transition from conventional data science operations to a separate Domain-Specific Language (DSL) environment.
This is ultimately the preference of the developer, but integrated environments reduce the need for context switching between model training, proving, and verification stages, thereby lowering the cognitive load and technical barriers. This unified approach allows users to concentrate more on analytical aspects and less on non-trivial procedural transitions between different workflow stages.
There are still significant optimizations to developer experience, technical implementation, and proving system compatibility to build. We hope this benchmarking serves as a useful reference to developers deciding on which framework to utilize, and also as a personal benchmark for EZKL to improve upon.